Disney created the character and was able to profit from it for years, but Disney has equally profited over characters it didn't create but instead created their own adaptations. Why should other companies be denied the same thing Disney had access to?
Depends imo. If it's purely just a few static pages then yeah I can see this happening but as soon as you have anything like a blog you're going to want some sort of content management system surely to manage it?
What I see this more doing is eliminating the need for someone to code the glue between the CMS and the website -- you can just ask the AI to add code to get your blogs from Contentful
> It's been clearly displayed that these tools are emitting verbatim copies of existing code (and its comments) in their input.
Which makes sense when you consider that the sort of code that is getting reproduced verbatim is usually library functions which developers may copy and paste verbatim comments and all into their project, especially when you prompt the AI with the header of a function that has been copied and pasted often, so the weightings will in that instance be heavily skewed towards reproducing that function
I think harder, as it is spammed around in all directions. It's easier to attribute a unique piece of code that appears in a single repo.
But boilerplate functions don't deserve copyright protection as they are not creative. Can I copyright print('hello world!') if I post it in my repo? Do I deserve a citation from now on?
For better or worse, AI is a combination of machine learning algorithms. And these algorithms are black boxes solely because we don't add observability to them - we aren't looking.
But there is a desire to understand why an AI provided the output it did (to increase trust in AI generated output), and so there's a lot of study and work going into adding that observability. Once that's in place, it becomes pretty straightforward to identify which inputs to a model provided what outputs.
I have never seen an ML researcher claim that understanding the effect of specific training inputs on outputs is straightforward given the size of these LLMs. Most view it as a very difficult if not impossible problem.
And yet it's a major part of the overall concept of being responsible with our use of AIs. Throwing our hands up in the air and prematurely declaring defeat is not an option long term.
It's a non-starter for no other reason than potential copyright infringement means the government becomes involved, and they will stomp on the AI mouse with the force of an elephant - the opinions of amateurs and the anti-copyright movement notwithstanding.
As such, AI Observability is a problem that's both under active research, and the basis for B2B companies.
Observability is great but it doesn’t give granular enough insights into what is actually happening.
Given a black box you can do two things: watch the black box for a while to see what it does, or take it apart to see how it works.
Observability is the former. Useful in many cases, just not here.
If you want to know what LLMs are actually doing, you’ll need the latter. Looking at weight activations for example, although with billions of parameters that’s infeasible.
"No they're not" and "no it's not" (simplified from the actual response) are conversation enders, so I'll follow the lead and let this conversation end.
Probably why, like the article says, they're planning to add that
> In an attempt to address the issues with open-source licensing, GitHub plans to introduce a new Copilot feature that will “provide a reference for suggestions that resemble public code on GitHub so that you can make a more informed decision about whether and how to use that code,” including “providing attribution where appropriate.” GitHub also has a configurable filter to block suggestions matching public code.
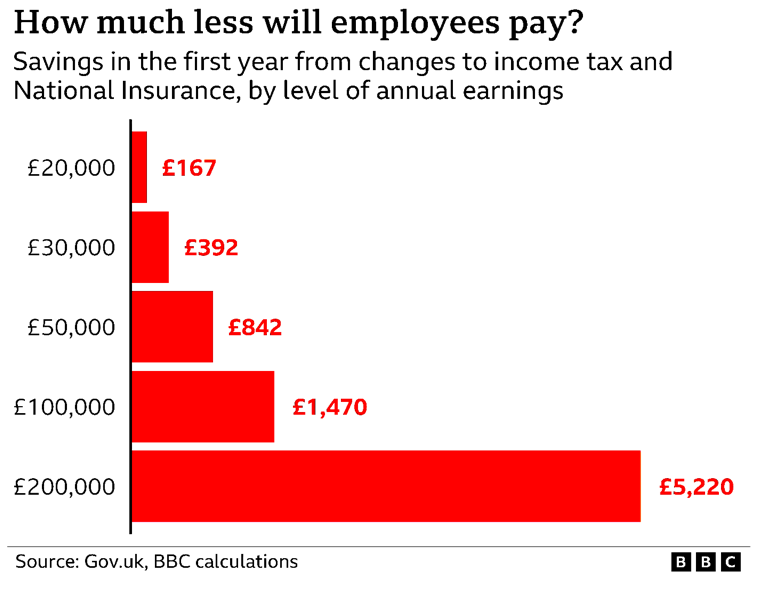
> Due to the insidious tax policy of withdrawing the personal allowance when income reaches £100K
The affect of removing that doesn't seem to be that major, with the figures [1] appearing to work out at almost 1.5% less tax for those on £100k, and a little over 2.5% less tax for those on £200k -- hardly a huge decrease in the tax burden for those people.
Financially: I am good at my job, work hard, and take on a lot of responsibility outside my formal JD, and it has advanced my career (and pay) dramatically faster than I could have advanced by working within a rigidly defined role with strict pay bands.
Ethically: I do not want a committee of mediocre coworkers telling me what responsibilities I am allowed to do 8 hours a day.
I would feel differently if I was a janitor, of course. So janitors should unionize! But I am a well-compensated software engineer and I have no interest in that employment structure.
See, maybe this is just a cultural difference but I definitely know unionized people who have taken on responsibility outside their formal JD
And I've definitely heard of non unionised companies with rigid roles like that where the middle managers liked having defined roles with little room for taking on additional responsibilities.
The difference between the two IMO is if the union has shit representatives you _can_ work with colleagues to get a different union rep as it's democratic when implemented correctly, whereas with a crap management you only have the option of moving job, so at least with a more unionised workforce you can do both.
The "left" is no more immune to controlling thought than the right -- just look at China or the USSR
The danger is authoritarianism and centralisation, and in terms of centralisation big tech companies like Spotify have in spades. You could also feasibly argue they're authoritarian as no-one outside the company can influence policy outside of free market forces, but centralisation can make these companies somewhat immune to said forces, for instance Spotify being the exclusive distributor of Joe Rogan podcasts means those interested in his content have no choice but to continue using Spotify, even though some of his podcasts have been removed.
> Because you know what happens when private property is abolished? Spoiler, only the well connected and powerful will hold private property
If only a few people can own private property then you haven't abolished private property, you've just limited who can own it.
This was the main issue caused by the massive state control of Marxist Leninist countries like the Soviet Union -- by centralizing all control within one single political party you essentially just replace an economic elite with a political elite. Couple that with the democratic centralism you often find in these single party ML countries and suddenly you have something that's a lot less like the communal living the OP was referring to.
I'm not saying abolishing private property will be some magical fix all, but I also don't think using the soviet union as an example of why it won't work is a good example. You could have a society where usage of resources is governed by consensus rather than "lol stalin said so" but consensus is obviously a lot harder to do on a global scale than a small communal village
Thanks, that was probably my point. Consensus is hard. Ethereum is one of the global systems that currently exists for tackling the consensus problem. Shouting at clouds is on the other hand, not tackling the consensus problem.
Someone or something has to be at the helm of the command economy. I'm definitely not saying we should "go back to communal living and producing stuff based on actual needs" but I am saying that without a rigorous system for distributed consensus, you really don't have a chance of achieving this.
{kind=link}